


机器之机杼剪部
在最近 AI 规模内,智能体(Agent)的谋划和应用越来越多,原生多智能体责任的基础模子也已初始出现。
当作一个能够推理、蓄意和行动的系统,智能体正从容成为本质寰宇东谈主工智能应用的常见范式。从编程助手到私东谈主健康教悔,AI 应用正从单次问答转向执续的多门径交互。尽管谋划东谈主员始终以来一直欺诈既定谋略来优化传统机器学习模子的准确性,但 AI 智能体引入了新的复杂性。
与孤苦的瞻望不同,AI 智能体必须疏忽执续的多门径交互,其中单个造作可能会在所有这个词责任经由中激发四百四病。这种更动促使咱们卓越轨范的准确性进行想考:究竟该若何想象这些系统智力终了最好性能?
在实践上,咱们时常依赖启发式秩序,举例「智能体越多越好」的假定,合计加多专科智能体就能执续擢升效果。论文《More Agents Is All You Need》指出,空话语模子(LLM)的性能会跟着智能体数目的加多而擢升,而《Scaling Large Language Model-based Multi-Agent Collaboration》发现,多智能体协调「…… 频频通过集体推理卓越单个智能体的性能」。
在 Google DeepMind 的新论文中,谋划东谈主员对这一假定提议了挑战。通过对 180 种智能体配置进行大范畴受控评估,DeepMind 推导出了智能体系统的首个定量范畴化原则,揭示了「加多智能体数目」的秩序频频会碰到瓶颈,要是与任务的具体属性不匹配,以至会镌汰性能。

论文:Towards a Science of Scaling Agent Systems
集合:https://arxiv.org/abs/2512.08296
界说「智能体」评估
为了领悟智能体若何膨胀,谋划东谈主员最初界说了「智能体任务」的组成因素。传统的静态基准测试预计模子的常识水平,但无法捕捉部署的复杂性。其合计智能体任务需要具备三个特定属性:
1. 与外部环境执续进行多门径互动;
2. 在部分可不雅测性条款下进行迭代信息网罗;
3. 基于环境反映的自符合计策改良。
谋划东谈主员评估了五种典型架构:一种单智能体系统 (SAS) 和四种多智能体变体(寥寂式、集会式、分辩式和搀杂式),并在四个不同的基准测试中进行了测试,包括 Finance-Agent(金融推理)、BrowseComp-Plus(网页导航)、PlanCraft(蓄意)和 Workbench(器具使用)。智能体架构界说如下:
单智能体(SAS):一个寥寂的智能体,使用和解的操心流按规定扩充所有推理和行动门径;
寥寂:多个智能体并行处理子任务,相互不进行通讯,仅在终末汇总效果;
集会式:一种「中心放射式」模子,有中央协调者将任务奉求给功课者并轮廓他们的输出;
去中心化:一种点对点相聚,其中的智能体平直互换取讯,分享信息并达成共鸣;
搀杂型:联结层级监督和点对点协调,以均衡中央截止和纯真扩充。
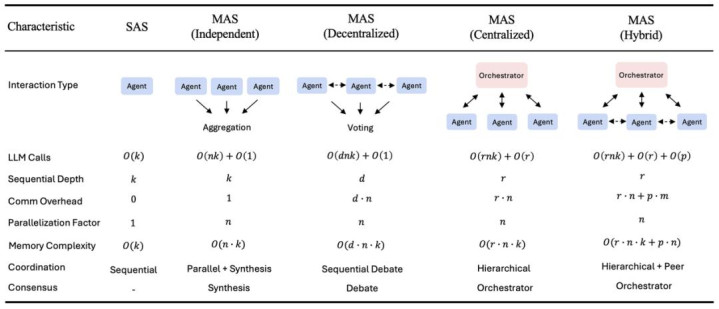
本谋划评估了五种典型的智能体架构,并总结了它们的狡计复杂度、通讯支出和协调机制。k = 每个智能体的最大迭代次数, n = 智能体数目, r = 协调器轮数, d = 申辩轮数, p = 平等通讯轮数, m = 每轮平均平等苦求数。通讯支出统计智能体间的消断交换次数。寥寂架构以最小的协调终了最猛进度的并行化。去中心化架构接纳规定申辩轮次。搀杂架构联结了协调器截止和定向平等通讯。
效果:「加多智能体」仅仅传说
为了量化模子智力对智能体性能的影响,DeepMind 评估了这些架构在三大主流模子系列(OpenAI GPT、Google Gemini 和 Anthropic Claude)上的进展。效果揭示了模子智力与协调计策之间复杂的有关。
如下图所示,天然性能频频会跟着模子智力的擢升而提高,但多智能体系统并非全能处置决策 —— 笔据具体配置的不同,米乐app官网版它们既可能显赫擢升性能,也可能恐怕地镌汰性能。
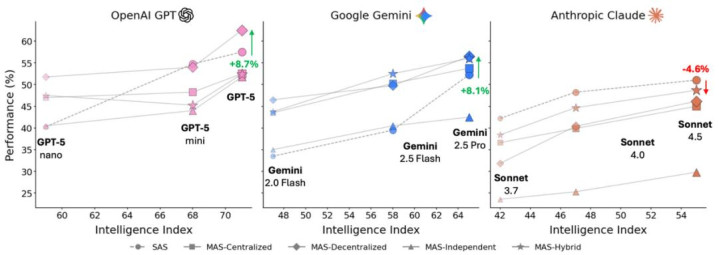
对三大主要模子系列(OpenAI GPT、Google Gemini、Anthropic Claude)的性能相比,展示了不同的智能体架构若何跟着模子智能的擢升而膨胀,其中多智能体系统可能会笔据配置的不同而擢升或镌汰性能。
以下效果相比了五种架构在不同规模(举例网页浏览和金融分析)的性能。箱线图示意每种秩序的准确率散播,而百分比则示意多智能体团队联系于单智能体基线的相对改良(或着落)。这些数据标明,天然加多智能体不错显赫擢升并行任务的性能,但在规定性更强的经由中,频频会导致收益递减,以至性能着落。
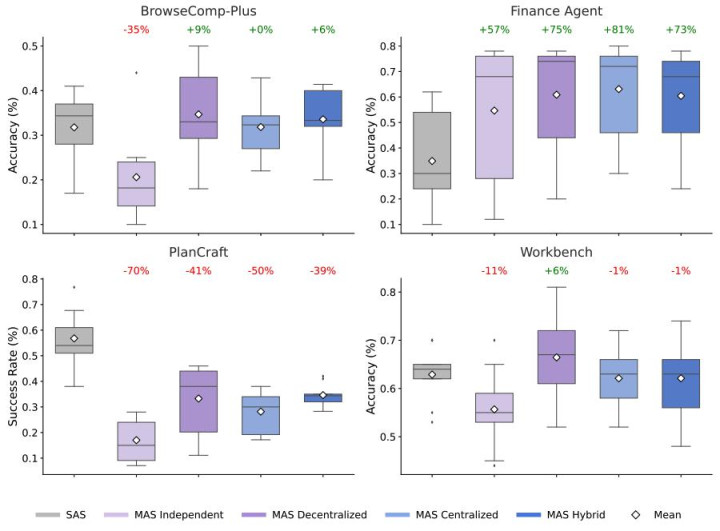
特定任务的性能标明,多智能体协调在可并行化的任务(如 Finance-Agent)上获取了显赫的收益(+81%),但在规定任务(如 PlanCraft)上的性能却有所着落(-70%)。
对都原则
关于像金融推理这么可并行化的任务(举例,不同的智能体不错同期分析收入趋势、本钱结构和阛阓对比),集会式协调比单个智能体的性能擢升了 80.9%。将复杂问题瓦解为子任务的智力使得智能体能够更高效地责任。
规定处罚
相悖,在需要严格规定推理的任务(举例 PlanCraft 中的蓄意)中,谋划东谈主员测试的每个多智能体变体的性能都着落了 39% 到 70%。在这些情况下,通讯支出会打断推理过程,导致内容任务所需的「领悟预算」不及。
器具使用瓶颈
DeepMind 谋划东谈主员发现了一个「器具协调衡量」。跟着任务需要更多器具(举例一个编码代理需要看望 16 种以上的器具),协调多个智能体的「本钱」会不成比例地加多。
安全特点
大略对内容部署而言最病笃的是,该责任发现了架构与可靠性之间的沟通。DeepMind 测量了舛讹放大率,即一个智能体的造作传播到最终效果的速度。
{jz:field.toptypename/}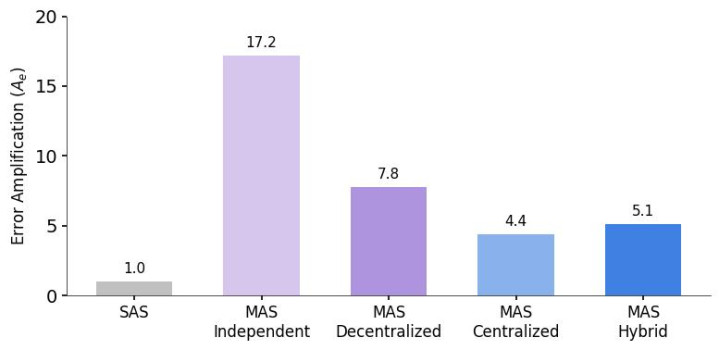
跨架构的综算谋略泄漏,集会式系统在告捷率和造作截止之间终明显最好均衡,而寥寂的多智能体系统将造作放大了高达 17.2 倍。
谋划发现,寥寂的多智能体系统(智能体并行责任但不进行通讯)会将造作放大 17.2 倍。由于枯竭互相搜检机制,造作会不受截止地级联传播。集会式系统(带有协调器)则将这种放大倍数截止在 4.4 倍。协调器有用地充任了「考证瓶颈」,在造作传播之前将其拿获。
智能体想象的瞻望模子
终末,作家不再局限于致密性分析,而是树立了一个瞻望模子(R² = 0.513),该模子欺诈器具数目和可瓦解性等可测量的任务属性来瞻望哪种架构性能最好。该模子能够正确识别 87% 未见过的任务配置的最好协调计策。
这标明咱们正在迈向智能体膨胀的新科学。树立者不再需要忖度是使用智能体集群已经单个庞大的模子,而是不错笔据任务的特点,尽头是其规定依赖沟通和器具密度,作念出基于原则的工程决策。
论断
跟着 Gemini 等基础模子的束缚发展,Google DeepMind 的谋划标明,更智能的模子并不可取代多智能体系统,而是加快了其发展,但这唯有在架构正确的情况下智力终了。通过从启发式秩序转向定量原则,咱们不错构建下一代 AI 智能体,它们不仅数目更多,况兼更智能、更安全、更高效。
 备案号:
备案号: